
Quoi de plus agaçant pour un utilisateur que de voir son application disparaître brusquement ou de voir apparaître un message totalement incompréhensible annonçant la fin imprévue du programme (ou un message du style "une erreur est survenue"!).
Le traitement des incidents est quelque chose à soigner tout particulièrement dès le début de la réalisation d’un code (ne serait-ce parce que ça va vous aider pendant la phase de mise au point!).
Plusieurs points à garder à l’esprit:
-
Il existe deux grandes catégories d’erreurs:
-
Les erreurs "normales" résultant des contrôles que votre code exécute sur des données.
Par exemple: un utilisateur veut acheter un
Produitmais le stock est épuisé; un utilisateur saisit un numéro de compte erroné, etc…. - Les erreurs résultant d’un fonctionnement anormal de votre code (un "bug"!)
-
Les erreurs "normales" résultant des contrôles que votre code exécute sur des données.
Par exemple: un utilisateur veut acheter un
-
Pour émettre des diagnostics pertinents on doit:
- disposer de diagnostics riches (des données qui peuvent être manipulées par d’autres parties de l’application). Si le code chargé de récupérer une erreur "normale" reçoit un message disant "plus en stock!" c’est idiot: il doit déclencher des traitements associés à un défaut de stock (et, donc, disposer des informations détaillées sur le produit, l’incident, etc.: ce sont des données par un texte!), le message à l’utilisateur est traité par un autre code -voir ci après la notion de rapport- .
-
disposer de moyen de distinguer les données de diagnostic des types de retour des formes fonctionnelles. En effet une fonction renvoie un résultat, le fait de lui faire envoyer aussi un diagnostic d’erreur:
- Complique considérablement le type de la valeur de retour
- Ne garantit pas que le code "appelant" tiendra compte de ce diagnostic
- forcer le code appelant à prendre en compte le fait qu’un incident s’est produit. (Cette fonctionnalité, implantée en Java, est contestée par certains).
-
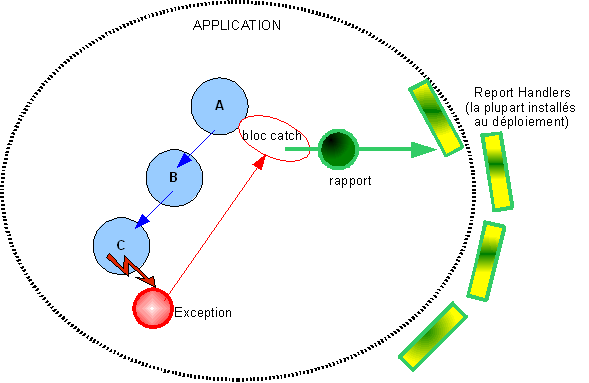
Une fois qu’on dispose d’un diagnostic le code appelant peut prendre des mesures appropriées et éventuellement émettre un "rapport" destiné à l’extérieur. A "l’extérieur" on doit considérer trois paramètres importants lorsqu’on veut traiter un rapport:
- QUI?
- A qui s’adresse-t’on? à un utilisateur final? à l’administrateur système? au programmeur en charge de la maintenance?
- QUOI?
- Un simple message pour l’utilisateur final? un message détaillé à l’administrateur? le contenu de la pile d’exécution pour la maintenance?
- COMMENT?
-
En utilisant l’interface graphique de l’utilisateur? la console de l’administrateur? en envoyant un courriel à la maintenance?
En fait le code réalisant ne se pose pas ces questions: il émet un "rapport interne". Le code appelant prendra les mesures appropriées et émettra le "rapport externe". C’est au reste de l’application (et, éventuellement, à la configuration) de savoir remettre ces rapports externes.
On a donc deux notions importantes distinctes: le rapport "interne" (souvent rendu par la notion d'exception) et le rapport "externe" qui relève du logging.
On notera que la notion de "rapport externe" (logging) englobe les rapports d’erreur, les traces, la journalisation …
Dans un langage comme Java les "rapports internes" sont des données définies comme étant
des Exceptions, les "rapports externes" sont des LogRecord, les gestionnaires de rapports savent mettre en forme et remettre les rapports "externes".
En Europe les langages (naturels!) diffèrent, les règles de taxation diffèrent, etc… Une application qui veut dépasser les frontières doit être configurable. En fait elle doit l'être dans tous les cas! Par exemple on peut vouloir une adaptation à un client particulier ou une adaptation à l'évolution des règles de gestion.
Ces adaptations peuvent être constituées de données (les messages traduits, les taux de TVA, l’image de la société courante,…) mais aussi parfois de codes (certaines données ne peuvent être configurées que par programme).
Il est important que le programmeur connaisse bien les stratégies de ressources implantées dans son langage. Il peut y avoir différentes techniques (les ressources d’internationalisation suivent souvent des stratégies spécifiques).
Une question lancinante est où se trouvent ces ressources?
Si c’est dans le système de fichier penser à la portabilité des codes: envisageriez vous de dire "sous WIN* voir à tel endroit, sous UNIX à tel endroit et sous MAC à tel endroit"? C’est à l’application se savoir où trouver systématiquement ses données et le programmeur de déploiement doit avoir une stratégie unique (si possible indépendante des systèmes d’exploitation). De plus penser que certaines ressources peuvent ne pas se trouver sur la machine courante mais sur un serveur, sur le WEB, etc…
Table of contents
-
Introduction à la programmation informatique
-
Programmer?
- 1. Qu’est-ce qu’un programme ?
- 2. Les éléments d’un programme
- 3. Les fonctions
- 4. Retour sur les types: quelques structures de données
- 5. Blocs de code, portée, modularité
- 6. Digression: Les symboles et la vision du bas niveau §§
- 7. Les types composites §§
- 8. La programmation "à objets"
- 9. Types fonction
- 10. Réflexion/Introspection
- 11. Types paramétrés
- 12. Recommandations générales
- 13. Conclusions §§
-
ANNEXE A: les langages de programmation
-
14. Comparer des langages de programmation?
- 14.1. Points de comparaison
- 14.2. Cobol, RPG
- 14.3. Basics
- 14.4. Php, Perl, Javascript
- 14.5. Autres paradigmes "exotiques"
- 14.6. C
- 14.7. Java, C#
- 14.8. Les "flots" fonctionnels
- 14.9. Langages d’enseignement
- 14.10. Langages spécifiques : SQL
- 14.11. Formalismes spécifiques : XML (et la famille SGML)
- 14.12. Langages spécifiques : langages de commandes
- 14.13. Langages spécifiques : les DSL
-
14. Comparer des langages de programmation?
- Annexe B: Les développeurs
- Annexe C : Glossaire
- Annexe D : Exercices: compléments et illustrations
-
Programmer?