Ce chapitre constitue une parenthèse dans le déroulement de l’exposé. Nous avons vu un certain nombre de notions et il serait intéressant de savoir ce qui se passe "sous le capot". On va donc regarder de plus près le niveau quasiment "physique" dans lequel se joue la gestion des données.
Un langage va utiliser une variable pour stocker une donnée :

-
La variable a un nom (
VariableX) mais, pour certains modes d’exécution, ce nom va disparaître dans le code machine généré. Les données correspondantes vont être stockées à une adresse dans la mémoire. -
La variable a un type (
Type) qui permet d’une part de savoir combien d’espace il faut réserver dans la mémoire et, d’autre part, d’interpréter les données qui sont situées à cet endroit. (mais nous avons vu qu’il existe des langages dans lesquels les variables ne sont pas typées )

Ce chapitre présente de manière simplifiée la façon dont certaines structures organisent les données en mémoire.
Un tableau stocke des données de manière contiguë en mémoire.
A la base ce sont des données de même taille; donc pour accéder à la Nième donnée il suffit de rechercher
à partir de l’emplacement mémoire du début du tableau, un emplacement situé à N x taille de la donnée

On peut aussi réaliser des tableaux qui gèrent des indirections en mémoire:
pour retrouver l'élément N on recherche une donnée à l’index N qui donne l’emplacement
de la valeur recherchée:
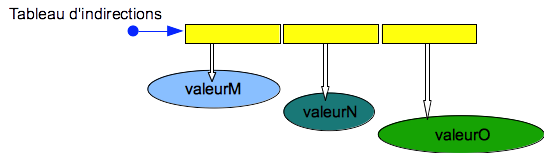
Selon les langages, dans un tel tableau les éléments qui permettent de réaliser l’indirection peuvent être:
- des pointeurs : c’est une donnée informatique qui réprésente une adresse en mémoire, le langage de programmation connait également la nature de ce qui est pointé.
- des références : c’est une donnée qui permet de retrouver une donnée en mémoire. Dans les langages qui utilisent des références les données stockées dans le tas peuvent se déplacer suite à une réorganisation du tas. La référence permet de retrouver la donnée même si elle s’est déplacée.
L’avantage d’un tel tableau est qu’il permet de stocker dans une même structure des données qui chacune nécessite une taille mémoire différente (par exemple des chaînes de caractères de tailles différentes).
Table of contents
-
Introduction à la programmation informatique
-
Programmer?
- 1. Qu’est-ce qu’un programme ?
- 2. Les éléments d’un programme
- 3. Les fonctions
- 4. Retour sur les types: quelques structures de données
- 5. Blocs de code, portée, modularité
- 6. Digression: Les symboles et la vision du bas niveau §§
- 7. Les types composites §§
- 8. La programmation "à objets"
- 9. Types fonction
- 10. Réflexion/Introspection
- 11. Types paramétrés
- 12. Recommandations générales
- 13. Conclusions §§
-
ANNEXE A: les langages de programmation
-
14. Comparer des langages de programmation?
- 14.1. Points de comparaison
- 14.2. Cobol, RPG
- 14.3. Basics
- 14.4. Php, Perl, Javascript
- 14.5. Autres paradigmes "exotiques"
- 14.6. C
- 14.7. Java, C#
- 14.8. Les "flots" fonctionnels
- 14.9. Langages d’enseignement
- 14.10. Langages spécifiques : SQL
- 14.11. Formalismes spécifiques : XML (et la famille SGML)
- 14.12. Langages spécifiques : langages de commandes
- 14.13. Langages spécifiques : les DSL
-
14. Comparer des langages de programmation?
- Annexe B: Les développeurs
- Annexe C : Glossaire
- Annexe D : Exercices: compléments et illustrations
-
Programmer?